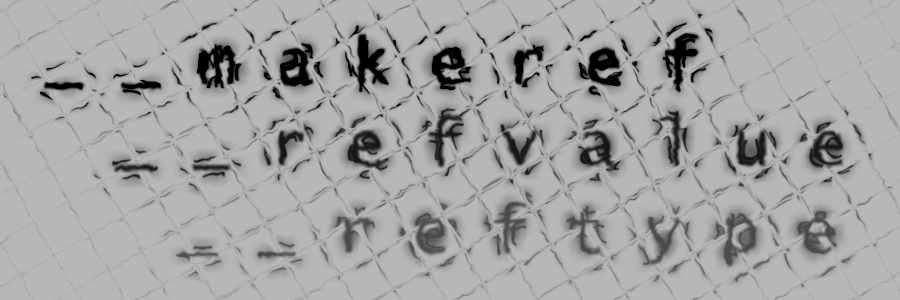
Table of ContentsTopWhat do these keywords do? What uses do these keywords have? Use Case: Generic Pointers Use Case: Runtime sizeof(T) Use Case: Reinterpreting Variables Comments Post DetailsFriday 13th May 2016Software Engineering performance c# Recommended PostsPostmortems - Absolutely Wrong (C#)Postmortems - Clearly Too Slow (Performance, C#) Three Garbage Examples (Performance, .NET) Common Multithreading Mistakes in C# - I: Incorrect Granularity (Multithreading, Performance) P/Invoke Tips (Native Interop, Performance) Common Multithreading Mistakes in C# - II: Unnecessary Contention (Multithreading, Performance) Common Multithreading Mistakes in C# - III: Unsafe Assumptions (Multithreading, Performance) |
Fun With __makeref
C#'s list of keywords is ever-growing, but there is also a set of four hidden (dark) keywords that have been in the language since its earliest days that not so many people are aware of.
Those keywords are: Today we'll be looking at __makeref and its two companion keywords __reftype and __refvalue. We won't be looking at __arglist today. What do these keywords do?__makeref is a C# keyword but it could be thought of and treated like a global standalone function that takes any value and returns a reference to it (like a reference in C++). In fact, using __makeref will 'return' a TypedReference, a less-well-known BCL struct in .NET.When we have a TypedReference, we can then use the other two relevant keywords (__reftype/__refvalue) to work with it. __reftype returns the System.Type of the the value we have a reference to (there is also a method on TypedReference to do this; personally though I prefer to stay consistent and use the three built-in keywords together). Finally, __refvalue either returns the value referenced to by the given TypedReference, or sets the value through said TypedReference. In case that didn't make much sense yet, here's an example showcasing all three keywords: Notice how with __refvalue we have to specify the type that xRef is a reference to (an int in this case). This is actually only for the programmer's benefit, so we can retain type safety. The runtime will throw an InvalidCastException if we try to treat xRef as a reference to a float, for example. What uses do these keywords have?Well firstly, let's talk about when not to use these keywords. The answer to this is fairly simple: You should almost never use these keywords. I think it's fairly obvious, but just in case, here's some reasons why:They make it possible to write unsafe and buggy code (as we'll see below)
Your colleagues will go mad searching for a function '__makeref' in scope (could be funny though)
Resharper doesn't recognise them
They are not documented or officially supported by MS (that being said, they've been ported to .NET Core and a surprising amount of code out there in the wild uses them)
So, in 99% of cases, they just ain't worth it! But now that we have that giant disclaimer out of the way, let's explore the interesting 1%. ;) Use Case: Generic PointersQuite a few people have lamented the lack of generic pointers in C# (that would look something akin to T* in a generic method or class). Although they might seem like a niche requirement they can be of huge use when working with native or interop code.For example, imagine a collection (like a std::vector) allocated in C++ whose elements you want to be able to access from C#. There is no way to build a generic way to access those elements in C# (i.e. some sort of NativeVector<T>). Even when not doing interop, using pointers and generics together is desirable in pure C#; for example when building fast off-heap collections like I/O ring buffers. The most well-known workaround is to build a small library or emit a collection of methods in IL, where generic pointers are possible. Some people try to use the Marshal.PtrToStructure and Marshal.StructureToPtr methods of the Marshal class. However, firstly, they're 10 times slower on my machine than the method I will show below (that's not an exaggeration, I measured it!); and more importantly, they don't work the way many people expect- for example sizeof(MyStruct) may not be the same as the number of bytes copied or read by these functions. That's because the Marshal class does as its name implies and marshals the data to C++ equivalents. This is also what's responsible for the reduced performance. Moving on, let's look at the TypedReference struct a bit closer. In fact, it's just two fields, a pointer to the variable we supplied to __makeref (that is our actual reference), and an internal pointer that represents the Type of the variable we took a reference to. The value pointer is the first field in the struct, and we can do some heavy unsafe abuse to use that pointer via a TypedReference. Here's a demonstration. Here we have an implementation of two methods, WriteGenericToPtr and ReadGenericFromPtr. The methods write and read a generic struct of type T to/from a pointer, respectively. I've explained the code line-by-line underneath. Here's an explanation of WriteGenericToPtr: [MethodImpl(MethodImplOptions.AggressiveInlining)] just tells the compiler/JIT that the given method should be inlined whenever possible.
public static void WriteGenericToPtr<T>(IntPtr dest, T value, int sizeOfT) where T : struct is our function declaration. dest is the pointer to copy the value struct to. sizeOfT is the size of the struct to copy in bytes. We constrain to a struct type because we're relying on the behaviour of value types being copied rather than passed-by-reference later on. Also, doing this sort of manipulation with reference types doesn't really often make much sense in the context of C#.
byte* bytePtr = (byte*) dest;: Here we're just casting dest to a byte* for use later.
TypedReference valueref = __makeref(value);: This line gets a reference to value. This would be like doing T* valuePtr = &value; if such a thing were allowed in C#.
byte* valuePtr = (byte*) *((IntPtr*) &valueref);: This is the nasty unsafe abuse I mentioned earlier. First of all we're getting a pointer to valueref (so that's a reference to our reference), and treating it as a pointer to an IntPtr instead of a pointer to a TypedReference. This works because the first 4/8 bytes in the TypedReference struct are an IntPtr� specifically the pointer to value. Then we dereference that IntPtr pointer to a regular old IntPtr, and finally cast that IntPtr to a byte* so we can use it in the copy code below.
Finally, we have a for loop (for (int i = 0; i < sizeOfT; ++i)) where we loop through each byte of value and copy it to the dest pointer. Remember, valuePtr is a byte* that points to the start of value on the current stack. We got that pointer by making a TypedReference to value with __makeref and then taking the pointer contained within that reference, which points to value.
And for ReadGenericFromPtr: public static T ReadGenericFromPtr<T>(IntPtr source, int sizeOfT) where T : struct is our function declaration this time. source is the pointer to copy the data from. sizeOfT is the size of the data in bytes.
Once again, byte* bytePtr = (byte*) source; is just a cast that we'll use in the for-loop later.
T result = default(T); is a way of allocating enough bytes on the stack for us to copy to, and will serve as our return value in a moment.
TypedReference resultRef = __makeref(result);: This line, similar to before, gets a reference to result. This would be like doing T* resultPtr = &result;.
byte* resultPtr = (byte*) *((IntPtr*) &resultRef); has exactly the same idea behind it as the similar line in the write method- we're getting the pointer to result.
This time, in the for-loop (for (int i = 0; i < sizeOfT; ++i)) we loop through each byte of the source data and copy it to result.
Now, if you're looking at this code and your first thought is "oh god why", I'd simply like to point out that code like this is fundamental for interop with native collections or for building fast unmanaged data structures. For example, using these two methods, we can now build a "NativeArray<T>" type that wraps a pointer to the first element in a C++ data-block or array, and it will work for any blittable struct type T, with no boilerplate required. Anyway, the alternative is to write or emit this code in IL, but that's not always preferable (and this is a blog post about __makeref, so go figure ;)). Now, if you're good at thinking ahead you might wonder where the sizeOfT parameter is meant to come from. After all, sizeof(T) doesn't work in C#... Use Case: Runtime sizeof(T)So as I just mentioned, there's no way to get the size of a generic C# struct type at runtime. sizeof(T) simply won't compile.Some people opt for using Marshal.SizeOf(). Just like before, those people are sitting on buggy code! So, let's try and do it with __makeref. In the interests of brevity, I'm gonna show you the crux of the implementation using __makeref first, but as a warning to anyone just scanning this page for code: There is a bug in the code below. The code after the example below will fix it, but if you're feeling like a challenge see if you can figure it out the bug on your own! So before we talk about the bug, let's talk about what the code is doing and how it works. The first line makes a new array of structs of type T, two elements in length. The next two lines then make references to the first and second elements in the array, via __makeref. That means that tRef0 and tRef1 are TypedReferences, each representing a reference to the corresponding T struct in tArray. Put simply, tRef0 is a reference to tArray[0], and tRef1 is a reference to tArray[1]. The next two lines get the actual pointers from the TypedReferences by using the same trick we used in WriteGenericToPtr/ReadGenericFromPtr. And finally, the last line measures the difference in bytes between the two pointers. This gives us the size of our T struct type, because array elements are guaranteed to be contiguous in C# (therefore by measuring the distance between the start of the first element in the array and the start of the second, we can calculate the size of the first element (and subsequently, all elements of type T!)). So, I mentioned a bug. Did you get it? Well, tArray is a normal array allocated on the managed heap, just like any other array in C#. As we know, all memory on the managed heap is subject to the whims of the garbage collector, and that includes being moved. Think what might happen if the GC pauses our application and moves the array after we get ptrToT0 but before we get ptrToT1. ptrToT0 will now point to the beginning of where the array was a moment ago, where as ptrToT1 will point to the second element in the array at where it has moved to. Needless to say, measuring the distance between these two pointers definitely will not give us a valid value for the size of T. So we need to fix that. Also, allocating GC'able memory and doing this stuff is a little unnecessary sometimes, if the type we're measuring is a primitive. So let's add in a little pre-check too. Here's the amended, bug-free, and slightly-kinder-on-GC-when-using-primitive-types code: Use Case: Reinterpreting VariablesAnd finally, I'm not going to go in to too much detail with this one as its uses are limited (though I did use it for converting between texel structs in my game engine). It's a way of freely converting any two structs of the same size between each other. There's nothing new in the code below, so if you've been following my explanations above (understandable if not ;)) then you should be able to understand this:So, in short, this allows us to treat a struct instance as though it was an instance of another. For example, if you're working with two identical Point structs from two different libraries, you can rapidly cast from one to the other using this. Anyway, that's it folks. I hope you enjoyed this; and I'll try and come back around with something more general for the next one. :) Edit 12th Jan '17: More recently, .NET Core has had a set of methods added that allow you to write a lot of the tricks discussed in this post in a fully-supported manner. See the following RTM Github commit for more information: https://github.com/dotnet/corefx/pull/7966 Read Next: Postmortems - Absolutely Wrong |