
Table of ContentsTopMultithreaded Code is a Relative Wild West Assumption 1: Atomicity Ensuring Read/Write Atomicity Are Word-Sized Variables Safe? Atomicity only Applies to Single Read/Write Operations Ensuring Atomicity for Compound Operations Assumption 2: Coherency Reordering Optimisations and Variable Caching Coherency Fixes Conclusion Comments Post DetailsSaturday 11th February 2017Software Engineering Common Multithreading Mistakes in C# multithreading performance c# Recommended PostsCommon Multithreading Mistakes in C# - IV: Everything Else (Multithreading, Performance)Postmortems - Absolutely Wrong (C#) Postmortems - Clearly Too Slow (Performance, C#) Common Multithreading Mistakes in C# - II: Unnecessary Contention (Multithreading, Performance) Common Multithreading Mistakes in C# - I: Incorrect Granularity (Multithreading, Performance) Fun With __makeref (Performance, C#) Three Garbage Examples (Performance, .NET) P/Invoke Tips (Native Interop, Performance) |
Common Multithreading Mistakes in C# - III: Unsafe Assumptions
In this series, I'm going to be elucidating some common errors C# programmers make when working with multithreaded systems. I'll be exploring issues from a lower-level point-of-view, and not dabbling too much in higher-level abstractions and libraries (such as the TPL and similar); hopefully the points raised will be pertinent to anyone hoping to write concurrent or parallelized applications.
Multithreaded Code is a Relative Wild WestIf you've been programming for a long time in more or less single-threaded environments, perhaps using things like the Parallel class or the TPL from time-to-time but never really diving in deep, then you may not be aware of the various pitfalls unique to multithreaded environments, especially when dealing with shared state.In this post, I'm going to look at some of the common assumptions people make about the way multithreaded code works that turn out to be wrong. Usually these mistakes are simply borne of programmers assuming that things work the same way they do in single-threaded applications, as well as not understanding the underlying hardware, compiler, and runtime memory models. Assumption 1: AtomicityContemplate the following code:Here we have a simple decimal property, backed by a field of the same type. In the code one thread is continuously writing a new value (2000 times), while a second thread is simultaneously reading it. Study the code: What output, if any, would you expect to see in the console? Well, here's an actual example output: So what's going on here? At no point do we write the value 6720.5: The highest value we do write is when i is equal to NUM_ITERATIONS - 1 (e.g. 19999 / 200 = 99.995). How could the reader thread possibly read a value almost 7 times higher? The answer is that we've accidentally got ourselves a torn read. You see, the underlying processor can write and read to/from memory locations only in 'word-sized' chunks (at least, between the cache subsystem and the registers). 'Word-sized' here means 32-bit or 64-bit, depending on your CPU. As decimal is a 128-bit type, when we write a new value to sharedState it must be written in either 2 64-bit chunks or 4 32-bit chunks (again, depending on your CPU). So imagine that our reader thread happens to read the value of sharedState exactly halfway through a concurrent write. It is quite possible in this case to read all 128-bits of the decimal value, but only the first or last 64 bits have been updated! In this case, half of the value we've read (in terms of the actual bits) is from the new value, and half of it is from the previous one. Incase that's not making much sense, here's a diagram demonstrating this series of events: 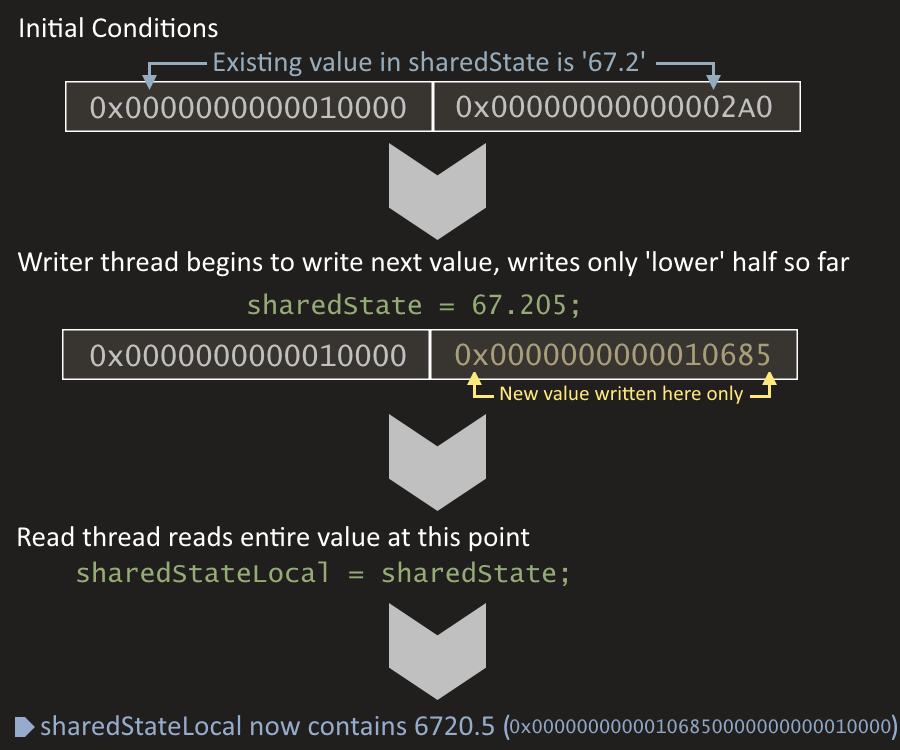
Of course, after our full read the writer thread completed its operation and fully wrote the actual value (67.205), but by then it's too late and we've got an invalid, half-and-half value 'out'. Ensuring Read/Write AtomicityIn single-threaded programs we don't usually see this behaviour because of course it doesn't matter how many parts a write must be done with, no read can be done concurrently. In multithreaded code, the best and almost-always most appropriate solution to accessing any shared state concurrently is, well, not to. But when it can't be helped, the next-best thing involves using well-thought-out thread-safety constructs.In this case, we want to make access to sharedState atomic. The word 'atomic' comes from the root atomicus meaning "indivisible"- basically we want to make our reads and writes indivisible with respect to each other. The easiest way to do this is with our friend the lock statement: With this simple change we've fixed the issue of atomicity: The console output remains completely blank no matter how many times we run the program. When working with 64-bit values in a 32-bit environment there is another option too: The Interlocked class has some methods explicitly for ensuring read/write atomicity. Imagine sharedState was a long rather than a decimal and that our code was going to be run on 32-bit target platforms. We could write this instead: The advantage to these methods is that under the right conditions they can be faster than using a lock. However, this is something of a micro-optimisation and you should prefer locks 99% of the time, only moving down to lock-free constructs like the one above if you've profiled your app and identified the lock as a hotspot. Are Word-Sized Variables Safe?So if you've followed so far and/or are a little ahead of the game here, you may be thinking "well it seems like 32-bit variables such as ints are exempt from this problem!". Well, firstly let's defer to the CLI Spec:"A conforming CLI shall guarantee that read and write access to properly aligned memory locations no larger than the native word size (the size of type native int) is atomic when all the write accesses to a location are the same size." That seems to confirm that native-word-sized-or-less variables (like int) are always atomic. However, notice the caveat "properly aligned". We're straying away from the "common" side of "common multithreading mistakes" here so I won't dwell on this point, but here's an example of code that can provide a torn read with longs even on a 64-bit runtime + system: I ran this on the 64-bit CLR on a 64-bit machine, but it prints out "Torn read! (somevalue)" many times a second. I'm not going to explain GetMisalignedHeapLong here (it's outside the scope of this post- but keep an eye out for the next!); but the important takeaway from this example is to remember that when you're dealing with unsafe (specifically memory allocated off the managed heap- possible with P/Invoke too) atomicity is no longer guaranteed even for word-sized values. Atomicity only Applies to Single Read/Write OperationsWhen dealing with a word-sized variable in regular C# then, are we safe? Well... "Safe" is a bit of a weasel term; but yes, reads and writes are atomic. However, something that many programmers get wrong is understanding that this only applies to a single read or write in isolation, and not a compound operation. Let's take a look at an example:This code simply starts four threads; each incrementing a global variable sharedState 100000 times. However, when the program is complete the console reads: Done. Value: 237884. Theoretically we should be expecting to see the value 400000, not 237884. Furthermore, the output is not stable w.r.t. multiple runs of the program. Every time I run this application I get a slightly different answer. The biggest reason we're seeing this is because although individual reads and writes of sharedState are atomic, compound operations are not. By 'compound operations' I mean a series or combination of reads or writes. To understand further, let's think about how the statement sharedState++ is expanded from the point-of-view of the CPU; demonstrated with C#-like "pseudocode": Here we can see that the statement sharedState++ actually compiles as a nonatomic read-modify-write operation. The read is done on the first line, a modification on the second, and finally the new value is written on the third. Whereas both the read and the write are themselves atomic, the whole operation itself is not. This is problematic because it means each threads' actions may be interleaved when modifying sharedState. If you're still not quite sure; let's think about a sequence of operations where two threads (WriterThread1 and WriterThread2) both attempt to execute the statement sharedState++ simultaneously. In the best-case scenario, you'd get something like this: WriterThread1: Read sharedState as '1341' in to register
WriterThread1: Add one to register
WriterThread1: Write '1342' to sharedState
WriterThread2: Read sharedState as '1342' in to register
WriterThread2: Add one to register
WriterThread2: Write '1343' to sharedState
In this case, both threads attempt to increment the value of sharedState by one and succeed. sharedState started at '1341', was incremented twice, and ended up at '1343'. However, imagine this alternative, equally possible order of operations: WriterThread1: Read sharedState as '1341' in to register
WriterThread1: Add one to register
WriterThread2: Read sharedState as '1341' in to register
WriterThread2: Add one to register
WriterThread1: Write '1342' to sharedState
WriterThread2: Write '1342' to sharedState
In this case, both threads read sharedState with the intention of incrementing it, but because of the order of operations both threads end up incrementing the same value ('1341') and although they both technically perform an increment, the final stored value is only one higher at '1342'. Of course, this phenomenon isn't just confined to increments. Any series of reads/writes that must be atomic is prone to this kind of error. Ensuring Atomicity for Compound OperationsJust like with reads and writes, ensuring atomicity for compound operations like this is easiest with a lock:This will ensure that the program always finishes with displaying an output of 400000. Those of you who have been following the series from the beginning may object to the use of a lock in this situation- although it's only an example, the addition of a lock has reduced the program down to worse-than-single-threaded performance wise. In other words, we've introduced unnecessary contention. For such an extreme example, using Interlocked.Increment instead of a lock would be reasonable: On my machine this is ~33% faster. However, this is also a fairly unusual case, and normally you won't see any kind of performance benefit in real terms from this kind of micro-optimisation. In most cases you should just use a lock. So that's the assumptions around atomicity wrapped up. Now let's look at a more insidious, less-well-known cause of problems! Assumption 2: CoherencyThe previous section ended up quite a lot bigger than I anticipated so I'm going to try and make this one short. But in essence, atomicity is not the only concern when dealing with unprotected shared state.Memory coherence (or coherency) is the principle of co-ordinating multiple simultaneous threads or cores into having a consistent, coherent 'view' of what the internal state of your program looks like. If we all still used a single-core CPU this would be pretty easy; but let's take a look at a simplified diagram of the memory and cache layout for a system with a modern dual-core processor: 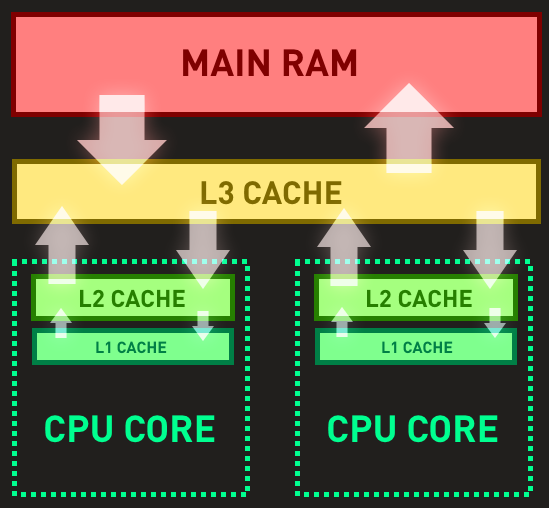
When writing code, we mostly think of our application's variables being stored and manipulated in RAM. But of course, reality is not so simple. When a variable must be modified, it is first loaded from RAM to the L3 cache, then on to the relevant core's L2 and L1 caches before finally being manipulated in the core itself. Most of the time these are but implementation details, and we as programmers can abstract this information away. When multithreading however, that abstraction can begin to leak. For now, study the following very simple code. Assuming that ThreadOneStart() runs on the first core, and is completely finished before ThreadTwoStart() starts on the second core, what would you expect to see written to the console? Most people would expect to see '100' written to the console. Well... The truth is, you will indeed see 100. But to expect that outcome is to actually rely on an imeplementation detail of the CLR! You see, when a CPU core usually writes to a variable, it doesn't always have to immediately 'commit' that change all the way up to RAM or the L3 cache. This means that for pretty much any variable write, the new value may just be 'sitting around' in that core's L1 or L2 cache. If later on the other core wants to read that value, it will just take the old, unchanged value from the L3 cache or RAM, unaware that its neighbour core has altered the value. Now, in reality, x86 CPUs don't do this for writes, so if you're on a desktop machine or common server architecture you're okay. Furthermore, because most target architectures that C# will ever run on have coherent writes in this way, the CLR currently enforces the behaviour on all platforms (by emitting something called a 'write barrier' or 'store/release fence'). However, these behaviours on the CPU and CLR level are both implementation details and there is no guarantee that things will stay the same in the future! In all likelihood, Intel/AMD will probably not change this in future CPU designs because it would risk breaking a lot of existing (incorrectly written!) software. However, the CLR may indeed change (and even has done for ARM targets). Take this quote from The C# Memory Model In Theory and Practice: "Consequently, the author might say something like, "In the .NET 2.0 memory model, all writes are volatile-even those to non-volatile fields." [...] This behavior isn't guaranteed by the ECMA C# spec, and, consequently, might not hold in future versions of the .NET Framework and on future architectures (and, in fact, does not hold in the .NET Framework 4.5 on ARM).". And that's not even considering new "runtimes" like .NET Native or Roslyn. For these reasons, although you will probably 'get away with it' currently, I personally consider it a bug when I see unprotected writes like in the example above. At any rate, it can get much worse, to the point where you go from technically having a bugged program to actually having one... Reordering Optimisations and Variable CachingConsider the following code:Like many of the examples that came before, it would appear at face value that we should never see "!!!" on the console... But if you've been following the trend here, you won't be surprised to learn that it is in fact possible! Why? Reordering optimisations! Firstly, on the CPU level, our friends the caches come in to play again. Processors usually have a cache coherency protocol (for example, MESIF on Intel or MOESI on AMD) that defines how and when data that is altered is propagated to the other cores. Sometimes, unless you insert explicit instructions called memory barriers, they may not immediately 'commit' certain writes to other cores. It is possible that a write that came earlier in time may actually be propagated/commited after a write that came later. This could lead to a scenario where Thread 2 can see valueWritten = true; before sharedValue = 1000;! Reads also work in a similar manner, and can also be reordered this way. Now, in reality, x86 writes are all effectively 'store-release' and will not be reordered with each other. Nor can reads be reordered with each other. However, reads and writes can be reordered! Not to mention of course the fact that you may be writing code that doesn't target x86. And even if you believe your CPU won't reorder your instructions, the C# compiler or JIT are still permitted to in certain cases! Finally, to add even more complexity, there's also the matter of variable caching. Take the following example: What value would you expect to see printed to the console for counter? Well... It's a trick question! loopThread never exits, so we never get past loopThread.Join(). Why? Because cancelLoop is cached. The CPU has no reason not to keep the cancelLoop variable in either the L1 cache or likely the actual CPU registers, because the code we've written makes no indication that cancelLoop could be changed from the loopThread. It's not the CPU's job to assume any variable might change on another core, because 99% of the time it won't and to keep checking just in case would be a huge performance drain. It gets worse however, as the C# compiler or JIT are permitted to make an identical optimisation and actually rewrite LoopThreadStart to look something like this: This is definitely no longer a theoretical either- on my machine the test program above was stuck in an infinite loop when I ran it. Coherency FixesAs always, the easiest fix is to use locks. As we know, locks provide atomicity for non-atomic operations. However, the entering and exiting of a lock also implicitly emits a memory barrier. Memory barriers act as their name implies, preventing reordering operations around them, and ensuring a certain degree of 'freshness'/'immediacy' when reading or writing (though for the sake of absolute correctness I feel I should point out that memory barriers are not in themselves 'flushes' in any way- they just enforce the global ordering of instructions which in turn can help prevent 'stale' values). Better yet, the developers of the higher-level .NET multithreading libraries have designed those libraries in such a way so that this sort of thing is taken care of for you behind-the-scenes, so I highly recommend sticking to those.Nonetheless, for the cached-loop example, we can actually explicitly emit a memory barrier inside the loop to fix the problem, like so: This fixes the infinite loop by forcing the CPU/compiler not to use a 'read' of cancelLoop that is older than the most recent memory barrier instruction; and by indicating to the C# compiler and JIT something similar. Nonetheless, all this stuff is very very complex, to even the point where when the great Linus Torvalds talks about it he finishes his remarks with "I think". So my advice? Just stick to the proper threading constructs provided for you in .NET, and don't assume that multithreaded code works in the same way as single-threaded code! ConclusionWhen working with a truly multithreaded environment there are some golden guidelines to help minimise the chances of running in to the errors I've described above:Avoid shared mutable state wherever possible. If your application has 8 threads all changing a slew of global variables simultaneously, you're gonna have a bad time. Try to formalize the inter-thread communication via a mechanism like channels, passing data formally rather than relying on 'watching' for changes.
Prefer immutability. If data can't be changed, then it's inherently more thread safe, and you bypass pretty much every issue talked about above.
If you must share mutable state between threads, synchronize access to that state appropriately. Don't even try and write 'lock-free' code unless you're an expert in that sort of thing. You'll want to at least lock over the accesses (reads/writes) to that data or better yet use the plethora of higher-level tools available to all us .NET programmers; such as the TPL, constructs like Semaphores and ReaderWriterLocks, async/await, and the Parallel class.
Also when working with multithreaded code, you need to have the right 'mindset'. To quote MSDN Magazine's October 2005 issue: "For a multithreaded program [...] it is better to think of all memory as spinning (being changed by other threads) unless the programmer does something explicit to freeze (or stabilize) it." I really like this advice. To put it in more generalised terms, you should consider all code thread-unsafe unless explicitly synchronized. 'Synchronized' can mean via a lock, or something higher level such as a Semaphore, the TPL, or even cross-thread invokers. For further reading, here is a great list of slightly more specific advice published by Intel: 8 Simple Rules for Designing Threaded Applications. Have a great day, and next time I'll be back with the last major part to this series, wrapping up with some miscellaneous mistakes that didn't fit the first three posts. Read Next: Common Multithreading Mistakes in C# - IV: Everything Else |