
Table of ContentsTopC# 12.0 Primary Constructors in non-Record Types Collection Expressions Improved Type Aliasing Default/Optional Lambda Arguments Experimental Attribute Inline Arrays Ref Readonly Parameters Comments Post DetailsMonday 27th November 2023Software Engineering Complete C# Quick Reference .net c# Recommended PostsComplete C# Quick Reference - C# 11 (.NET, C#)Complete C# Quick Reference - C# 10 (.NET, C#) Complete C# Quick Reference - C# 9 (.NET, C#) Complete C# Quick Reference - C# 8 (.NET, C#) Complete C# Quick Reference - C# 7 (.NET, C#) Complete C# Quick Reference - C# 5 and C# 6 (.NET, C#) Complete C# Quick Reference - C# 2, 3 and 4 (.NET, C#) |
Complete C# Quick Reference - C# 12C# 12.0Compared to some previous releases, C# 12 is quite a small, incremental update to the language. Here's the feature summary:Primary Constructors in non-Record TypesYou can now define a "primary" constructor for a non-record class or struct alongside the name of the type (similar to the primary constructor syntax for records):Unlike with record types, a primary constructor on a regular class/struct type does not automatically induce the generation of matching properties: So what's the advantage here? The biggest reasoning for this feature is that it cuts down on some unnecessary ceremony for types that tend to just assign their constructor parameters through to fields/properties anyway. Here's a "before and after" using an example from the official docs: So it does cut down on quite a bit of "noise", but I personally have some reservations about this feature: You can't validate parameters (e.g. check for null or out-of-range values). Most of the real-world types I write usually require constructor parameter validation. There are the occasional "plain old data" types that don't, but...
...I don't often see types that have constructor parameters that don't need additional validation/sanity checking but also wouldn't benefit from being a record type in the first place, including the value-semantics (and we already had this syntax for record types).
The naming convention for the parameters clashes with those for primary constructors in record types. For records I've always used PascalCase in order to have the auto-generated properties correctly be in PascalCase (e.g. sealed record class User(string Name, int Age)), but with non-record types the examples in the official documentation all use camelCase. You could declare non-record primary ctor parameters as PascalCase also (going against the conventions set by the examples for the feature), but PascalCase in C# has always traditionally implied a non-private member, and the generated fields are private. Also, personally, I prefer the _underscorePrefix convention for private fields anyway.
Familiar operations such as calling base-class constructors, constructor chaining, and even just finding where fields/values come from in a class now have a "second" way to do them that you need to learn and look out for. That is true of primary constructors in record types too, but the auto-generation of value-semantic-supporting methods and properties make the tradeoff more appealing in my opinion.
Perhaps worst of all, I don't like that this leaves a mutable field 'hiding' in your class/struct (conversely, record types generate init-only properties by default). I'm personally a huge proponent of the idea that all types should be immutable-by-default, and saving myself a bit of syntax at the cost of making my type privately-mutable doesn't really appeal. Even if I could validate the constructor parameters, the fact that the values might be altered anywhere elsewhere in the type post-construction makes it much harder to reason about the overall safety of the class/struct. Yes, they're only private fields, but that still bothers me.
Having said that, you can mark a struct with a primary constructor as readonly, which means the compiler will generate readonly fields, and you can not accidentally modify them anywhere. But I'd argue even more strongly that you almost always want a record type for a struct anyway.
It should be noted that the compiler only creates a field to 'back' your primary constructor parameters if you attempt to use them in any method, set them from a property, or do anything other than simply assign them to a property (e.g. public string Name => name + " test"; still generates a field, but public string Name => name; does not, it just assigns the property at construction time). Somewhat of a moot point, though.
Here's an example of how the constructor parameter becomes a mutable field and how that can be undesirable: Mutable fields open you up to an entire class of programmer-error/bug. The mistake shown above is simply impossible to commit when using immutable fields. You can technically 'hide' the parameters by redeclaring the fields as readonly: ...But now we're almost back to the same amount of 'boilerplate' we had before the primary constructor was added, and introduced another ostensibly-odd syntax construction (e.g. the name = name in the field initializer). So honestly, I probably won't be using the feature in my codebases in its current form. If you want to eschew parameter validation and constructor boilerplate, I'd consider required members as an alternative route (because the properties can still be declared as init-only), or just use records. I suppose this addition to the language does close a gap in syntax between record and non-record types, but even then the convention regarding camelCase vs PascalCase in the parameter declarations is still off-putting. I have read around and it's being considered to add a readonly modifier (or similar) for the parameters in a future version-- I may revisit the idea then. Collection ExpressionsThis is a syntactical addition that makes it easier to initialize various collection types, and probably the most useful addition in C# 12 for me (especially when writing unit tests). The actual feature is quite small though, and I think it's easiest to just explain using various examples:The full rules governing what type a collection expression will actually return are viewable in the language proposal. Improved Type AliasingYou can now using alias any type; including pointers, value tuples with named parameters, and function pointers:Default/Optional Lambda ArgumentsThis small change makes it possible to declare a lambda (e.g. an anonymous function implementation) that has optional parameters, and also one that takes a params argument:In the first example, multiplierFunc is declared with an optional parameter 'numMultiples'. When we invoke it on the next line we allow the default value of 2 to be used (notice how we only pass one argument to the delegate).
In the second example, joinFunc is declared with a single params parameter. On the next line, we pass three strings to the delegate as our params arguments.
You might think that the type of multiplierFunc is Func<string, int, string>, and the type of joinFunc is Func<string[], string>, but the compiler makes this feature work by creating hidden types for each delegate:  The type of multiplierFunc is actually f__AnonymousDelegate0<string, int, string>
The type of multiplierFunc is actually f__AnonymousDelegate0<string, int, string>
This means that this syntax does not work for non-implicitly-typed members or variables (including class members): There are probably use-cases for this I'm not thinking of, but when we already have full local functions I'm not sure how often I'll use this feature. Experimental AttributeThis attribute can be applied to anything in a codebase (including the entire assembly) to indicate that the type/member/assembly is experimental. When any user consumes that annoted target their compiler will emit an error letting them know that they're using a construct that may change or be removed in the future:The error can be bypassed either by marking your own code as Experimental also, or by explicitly permitting the experimental code through with a compiler pragma: Inline ArraysThis performance- and interop-oriented feature allows creating structs that have a fixed-length 'array' of contiguous elements contained within them. The following shows an example of a struct that encapsulates three strings:In terms of memory usage/layout, this is equivalent to creating a struct that declares three separate consecutive string fields. And accordingly, unlike with fixed-size buffers, you can use this feature with any non-pointer type (managed references will be tracked by the GC as normal). Interestingly, that last example actually crashes the compiler currently, but it's a known bug and will be fixed in an upcoming patch release.
You can do anything else you'd normally do with a struct type, including implementing interfaces: The interface implementation is required if you want to pass an inline array to a method that expects an IEnumerable. However, the compiler can rewrite a foreach loop to a for loop for you around the buffer automatically, even without the implementation: The foreach and for loop result in almost identical MSIL: 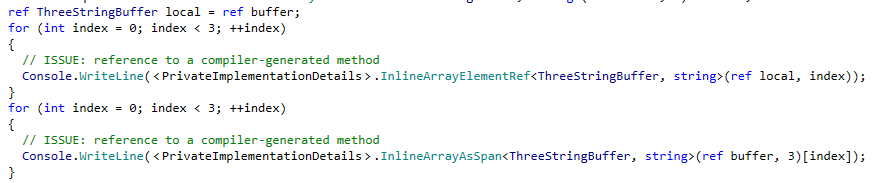 Top implementation is the foreach loop output, bottom is the for loop
Top implementation is the foreach loop output, bottom is the for loop
Finally, inline arrays are implicitly convertible to Span<T> and ReadOnlySpan<T>, which means you can pass them as-is to methods that consume spans: One last note: The official docs currently say that you can create an inline array type using a collection expression. However, this isn't actually the case yet.
Ref Readonly ParametersThis new parameter modifier indicates that an argument passed in to a function should be passed by ref, but that the value the reference refers to can not be modified:Without the readonly demarcation on ref readonly int i we could happily reassign i to be 3 inside TryAdjustRefReadonly. You may be wondering what the difference is between this new modifier and the pre-existing 'in' modifier. In a nutshell, we can explain the difference with the following bullets: in as a modifier is somewhat "hidden" to the consumer of the function at the call-site. It converts the argument from being pass-by-value to pass-by-reference but in a mostly invisible way. There is no need to annotate the in argument with ref at the call-site (in fact, until C# 12 this invoked a compiler error), because the value can not be modified anyway; in parameters are purely a performance optimisation chosen by the function author (you can annotate with in if desired or necessary for overload resolution).
ref readonly as a modifier, broadly speaking, has the opposite philosophy; it wants to make it explicit that you're passing in a reference. Whereas in is arguably only ever used as a performance optimisation, ref and ref readonly can be used to deliberately and obviously indicate that a reference to a value is being passed for reasons relevant to the treatment of the given argument.
The implication of this clear separation is more than just cosmetic. The compiler will emit warnings when you use in or ref readonly with different types of values (e.g. rvalues vs lvalues) incorrectly or suspiciously: In a nutshell, use ref readonly when you specifically want a reference to a value that has a memory location (e.g. the constructor of ReadOnlySpan<T> has been updated to use ref readonly rather than in), and use in when an rvalue (such as a constant, e.g. 123) is perfectly acceptable. Read Next: Complete C# Quick Reference - C# 11 |